Label Influence Propagation
Paper:Multi-Label Node Classification with Label Influence Propagation
针对图数据中多标签节点分类(MLNC)任务,研究人员提出了一种名为LIP的新模型。该模型通过分解GNN的消息传递过程,量化标签间的相互影响,并利用标签影响图调整学习过程,在多项基准测试中超越了现有方法。
现有解决多标签分类的三类策略
忽略标签相关性
独立的二分类预测
将标签视为一种新的节点类型并纳入原始图
通过节点与标签节点之间的传播和聚合信息来提高任务性能
缺点:在训练集中只有节点和标签节点之间的不完全连接
将标签表征整合到邻居聚合和分类过程
作为一种外部知识或隐式表示,巧妙地融入到GNN的邻居聚合和最终的分类器中,用的前述的用的标签同配性和跨类邻域相似性
改进工作
- 解决多标签图结构的模糊性【CorGCN】
- 解决多标签任务的有限表达能力
现有策略的局限性
低估了图数据中复杂的标签关联,未能充分利用这些关联来提升MLNC性能。
解耦GNN
解耦GNNs通过分离传播(P)和转换(T)操作,解决了传统GNNs过平滑问题,提高了效率和性能。本文受此启发,专注于分析P和T操作中标签影响关联,而非设计特定操作或增强模型容量。
方案创新点
实验观察到:标签间存在正负影响。训练时,若性能优于单独训练,则为正向影响;反之则为负向影响。通过分析和量化这些复杂的标签对图形的影响,以增强或减轻正面或负面影响。
LIP的核心思想是捕捉标签间的相互影响,并据此指导模型训练,以鼓励或抑制特定标签的学习。这包括量化标签间的相互影响关系,进一步捕捉高阶关系,计算每个标签损失的重要性得分,最终结合损失与重要性得分来优化MLNC任务。
MLNC PIPELINE
共享组件
一个图编码器(GCN、GAT 等)。输入图的邻接矩阵 A 和节点特征矩阵 X。输出所有节点的共享嵌入矩阵 Z,作为节点的通用特征表示,被所有标签的预测任务共享。
\[\mathbf{Z} = \Phi_\theta(\mathbf{A}, \mathbf{X})\]私有组件
每个标签对应一个独立的分类器。输入共享嵌入Z,输出每个标签的预测结果
\[\tilde{\mathbf{y}}_j = \psi_j(\mathbf{Z}).\]总览
消息传递分解为传播(P)和转换(T)操作
- P步骤:通过拉普拉斯平滑聚合邻居信息
- T步骤:应用非线性变换捕获训练样本数据分布。
P和T操作相互独立,其量化影响可结合,作为计算高阶影响关联的基础。
P过程影响量化
- 节点对之间的影响
通过测量 $V_i$ 输入特征变化对 $V_j$ 节点嵌入的影响来量化。
\[I(i,j) = \frac{\partial \mathbf{z}^{(k)}}{\partial \mathbf{z}_i^{(0)}}\]证明了该影响与特征无关,与个性化PageRank(PPR)分布成比例。最终可以如下计算出任意一对节点之间的影响相关性:
\[\mathrm{INF}^P(v_i, v_j) = \left\{\alpha\left(\mathbf{I}_n - (1-\alpha)\tilde{\mathbf{A}}_{\mathrm{sym}}\right)^{-1}\mathbf{s}_{v_i}\right\}_{v_j}\]- 标签集之间的影响
标签集 $Y_a$ 对 $Y_b$ 的影响通过整合所有节点对的影响来计算。直接求和会丢失正负影响方向的信息。
经过分析:不重叠的 $Y_a$ 节点对 $Y_b$ 产生负影响,而与重叠的 $Y_a$ 节点则中和了正负影响。
\[V_{neg} = Y_a \setminus (Y_a \cap Y_b) \to Y_b,\] \[V_{pos} = \overline{Y_a} \setminus \overline{Y_a \cup Y_b} = \overline{Y_a} \cap Y_b \to Y_b,\]V过程影响量化
共享GNN骨干网络通过模型参数从训练数据中学习。不同标签对参数更新的方向和幅度有不同要求,导致标签在反向传播过程中通过梯度下降相互影响。本文使用二元交叉熵损失计算每个标签的梯度。受梯度冲突定义启发,提出通过计算两个损失梯度之间的角度,即余弦相似度,来量化转换操作中的标签影响。角度越大,正向影响越不显著,反之负向影响越小。
\[\mathcal{L}_{\text{bi}}(\mathbf{y}, \hat{\mathbf{y}}) = -\frac{1}{M} \sum_{i=1}^M \left[ y_i \log(\hat{y}_i) + (1 - y_i) \log(1 - \hat{y}_i) \right],\] \[\nabla_{b_i} = \frac{\partial \mathcal{L}_{\text{bi}}}{\partial \Phi_\theta}.\] \[\text{INF}^T(a, b) = \text{INF}^T(b, a) = -\sum_\theta \text{ANGLE}\left(\nabla_a, \nabla_b(\theta)\right),\]标签图上的影响传播与损失函数
通过乘法结合得到最终标签影响关系矩阵InfMAT:
\[\mathrm{INFMAT} = \mathrm{INF}^P * \mathrm{INF}^T,\quad \mathrm{INFMAT} \in \mathbb{R}^{k \times k},\]为分析高阶关联,将InfMAT转换为标签图,其中节点为标签,边为标签间影响关联,通过Softmax归一化处理正负值。
\[G_{LIP} = \left(\mathcal{V}_y, \mathbf{A}_{LIP}\right),\quad \text{with}\; \mathbf{A}_{LIP} = \text{SOFTMAX}_{\text{row}}(\mathrm{INFMAT}),\]通过PageRank计算标签图上每个标签的重要性得分R,以量化高阶影响传播:
\[R = \left(\mathbf{I}_h - \beta \mathbf{A}_{LIP}\right)^{-1} \left( \frac{1-\beta}{h} \right) \mathbf{1},\]最终,LIP将R作为系数加权到每个标签的二元交叉熵损失上,从而鼓励正向影响标签,抑制负向影响标签,优化MLNC任务。
\[\mathcal{L}_{\text{LIP}} = \sum_{j=0}^k R_j \mathcal{L}_{\text{bi}}(\hat{\mathbf{y}}_j, \mathbf{y}_j),\]实验复现
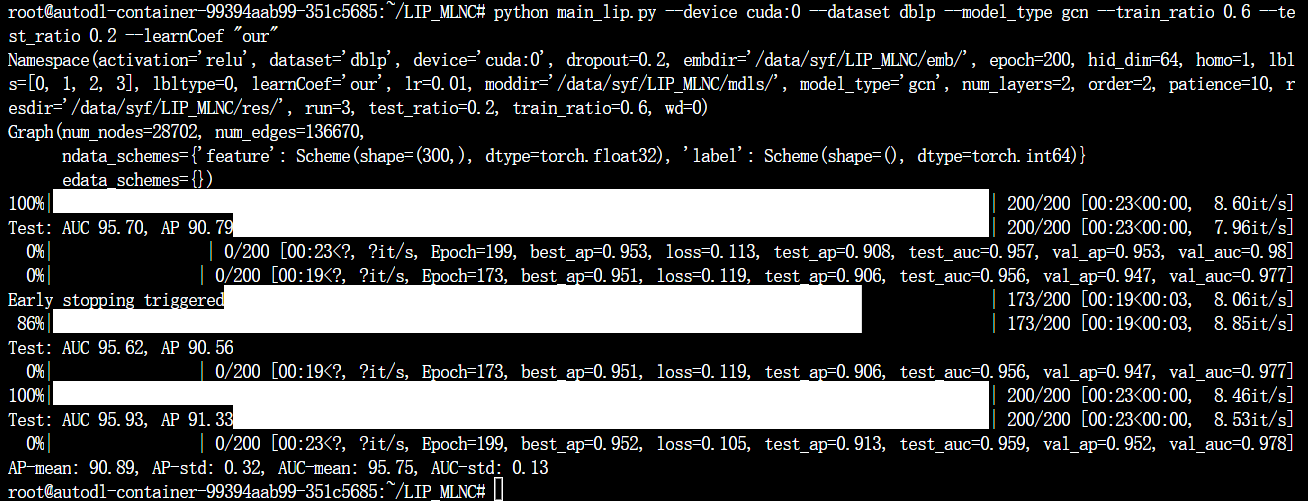
环境:Autodl平台,RTX4090,PyTorch 2.0.0,Python 3.8(ubuntu20.04),CUDA 11.8
任务:基于 DBLP 数据集训练 GCN 模型
python main_lip.py --device cuda:0 --dataset dblp --model_type gcn --train_ratio 0.6 --test_ratio 0.2 --learnCoef "our"
结果:AUC 均值 95.75%、AP 均值 90.89%